OOM in Production, Why?
I recently looked into an OutOfMemory exception in production and the culprit turned out to be the following code.

The application receives a response from a web service and needs to pass the result as a String into a field to a downstream web service. The downstream web service was old, and doesn't support prefixes. So a developer writes the above code to remove prefixes and also change a field name. Not an ideal situation but Innocent enough?
However, when the return xml from the first web service turns out to be pretty big, in the size of ~200k, it causes frequent OutOfMemory exceptions in production servers. 200k is pretty big for simple texts, but still, the server has 1.5G heap size, why is it OutOfMemory?
Java String Impementation is NOT Optimized for Large String
JVM hates large objects. The heap may have enough space, but it is always highly fragmented. When a large object request comes in, JVM will usually go through a series of gc cycles to move objects around to accomodate the large object. In my case, it is unfortunate that the input String is huge already, ~200k, the above code makes even more copies of it, stressing out JVM and resulting in OOM.
In the above code, each parse result is a new large String, which makes it 4 additional large objects. But that is not ALL! More large objects were allocated in Java's String implementation.
replaceAll is not optimized for large Strings

Always specify size when StringBuffer is created for large Strings
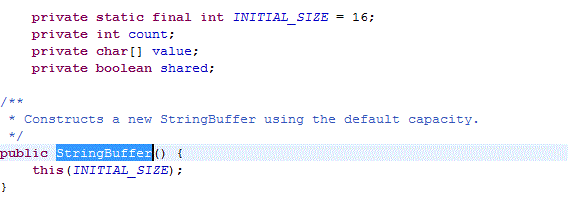

For large Strings, StringBuffer.toString() is bad, use new String(StringBuffer) instead

It checks the size of wasted bytes: if it is more than 768, it uses a different String constructor to make another copy of its underlying char array to free up 'wasted' space.

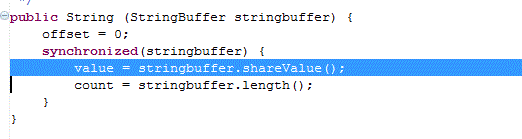
Always be extra careful with large Strings, read Java's source code when in doubt
Code Optimized
Eventually we decided to parse the String manually instead of using replaceAll. This allows us to transform the input String in one single pass and avoid generating additional large Java objects.

Code didn't worked for me.
ReplyDeleteHelpful. Thanks for sharing.
ReplyDelete